
How to use Apple Pay on Amazon
Amazon Prime Day is finally here! Avid shoppers keeping their eyes on exclusive Prime Day
2023-07-11 06:46

What does ‘P for Papas’ mean? Cat dance trend goes viral on TikTok
The fun and playful ‘P for Papas’ trend will have you grooving and singing along with your kitty, making for some adorable and heartwarming content
2023-05-28 14:54

Twitter objects to Turkish court orders after pre-election warnings
ISTANBUL (Reuters) -Twitter said it had filed objections to Turkish court orders requesting a ban on access to some accounts
2023-05-16 18:50

'Me at My Wedding': How to try this funny TikTok trend going viral?
TikTok trend 'Me at My Wedding' has taken the social media sphere by storm, attracting both men and women to participate in this hilarious challenge
2023-05-09 18:52

How to Play Urzikstan Early in Call of Duty: Modern Warfare III
To play Urzikstan early in Call of Duty: Modern Warfare III, fans must play Zombies mode to experience the new Warzone map before it launches.
2023-11-09 03:28

Elon Musk says X, formerly Twitter, will have voice and video calls, updates privacy policy
Elon Musk says his social network X, formerly known as Twitter, will give users the ability to make voice and video calls on the platform
2023-09-01 02:28

Scientists discover human groups that were long thought to be extinct are still alive
A recent finding in South Africa has rediscovered a human population that was thought to have been lost. When some languages from the Namibia Desert died out, anthropologists feared that the populations that spoke them had gone with it. However, researchers have discovered that the genetic identity of these once-thought lost populations may have been maintained, even without their native tongue. Southern Africa holds some of the greatest human genetic diversity on Earth, and it is a common pattern that this diversity suggests it is where a species or family originated. Even without fossil records, anthropologists would know humans evolved in Africa, simply by looking at how much greater the biological diversity is there. It is among the inhabitants of the Kalahari and Namibia Deserts of south-eastern Africa where this diversity can be seen most dramatically. "We were able to locate groups which were once thought to have disappeared more than 50 years ago," Dr Jorge Rocha of the University of Porto said in a statement. One of these groups is the Kwepe, who used to speak Kwadi. The disappearance of the language was thought to mark the end of their serration from neighbouring populations. Dr Ann-Maria Fehn of the Centro de Investigação em Biodiversidade e Recursos Genéticos said: "Kwadi was a click language that shared a common ancestor with the Khoe languages spoken by foragers and herders across Southern Africa." The team managed to find the descendants of those who spoke Kwadi, and discovered that they had retained their genetic distinctiveness that traces back to a time before Bantu-speaking farmers moved into the area. “A lot of our efforts were placed in understanding how much of this local variation and global eccentricity was caused by genetic drift – a random process that disproportionately affects small populations and by admixtures from vanished populations,” said Dr Sandra Oliverira of the University of Bern. "Previous studies revealed that foragers from the Kalahari desert descend from an ancestral population who was the first to split from all other extant humans,” added Professor Mark Stoneking of the Max Plank Institute for Evolutionary Anthropology. “Our results consistently place the newly identified ancestry within the same ancestral lineage but suggest that the Namib-related ancestry diverged from all other southern African ancestries, followed by a split of northern and southern Kalahari ancestries." The research allowed the team to reconstruct the migrations of the region's populations. With the Khoe-Kwadi speakers dispersed across the area around 2,000 years ago, possibly from what is now Tanzania. The populations that once spoke Kwadi, before adopting Bantu languages in recent decades, are the missing piece in the history of humanity as anthropologists identified in this study. The study can be read in Science Advances. Sign up to our free Indy100 weekly newsletter Have your say in our news democracy. Click the upvote icon at the top of the page to help raise this article through the indy100 rankings.
2023-09-27 19:18

South Korean firms get indefinite waiver on US chip gear supplies to China
Samsung Electronics and SK Hynix will be allowed to supply US chip equipment to their China factories indefinitely without separate US approvals, South Korea's presidential office and the companies said on Monday.
2023-10-10 11:50

Which celebs are on Instagram Threads? A-listers make early entry to Meta's new 'Twitter-killer' app
Meta’s new app, Thread, was unveiled on Wednesday, July 05, a day before its supposed release date
2023-07-06 13:45
Breckie Hill's Snapchat leaks prompts influencer to speak out
TikTok star Breckie Hill claimed she is being “sued” by her ex-partner amid a recent Snapchat leak. The 20-year-old social media star addressed the ongoing issues of videos leaking from her phone, revealing in a TikTok that her mobile phone number had been shared online, and she was being bombarded with calls from her millions of fans. But it’s not the first time the influencer has been hacked. In fact, in one TikTok she claimed it is the third time it has happened to her. In another since-deleted video, she addressed the situation. According to HITC, Hill uploaded a video on 26 July in which she alleged her former partner is suing her over leaked files, which many have presumed to contain intimate content. She wrote: “POV your ex is now trying to sue you for being in something that was leaked which wasn’t even your fault.” Hill has deleted four recent videos from her TikTok that reference the leaks. In one of them, she claimed there were a total of 709 files that has been compromised. Sign up to our free Indy100 weekly newsletter @breckiehill_ Responding to one commenter who suggested that Hill had leaked the files herself, she replied: “This comment is actually really disturbing to me. Why would I purposefully cause myself stress, anxiety, and tears to put photos of me as a child on the internet, including my number, including my email?” She added: “Maybe you should be more considerate next time and try putting yourself in that position.” @breckiehill Replying to @Alissa?? According to reports, Hill is working with a private investigator to discover the person that hacked her account and leaked the content to bring them to justice since she is only 17 years old in some of the images. Have your say in our news democracy. Click the upvote icon at the top of the page to help raise this article through the indy100 rankings.
2023-07-27 21:17

Race the virtual Formula 1 Las Vegas Grand Prix circuit before the big race in F1 23
Gamers can race the brand new track before the Las Vegas Grand Prix in 'F1 23'.
2023-05-25 20:24

Ransomware criminals are dumping kids' private files online after school hacks
Ransomware gangs have been stealing confidential documents from schools and dumping them online
2023-07-05 15:57
You Might Like...

Master Microsoft Excel with this training bundle, only $29

US to invest $1.2 bn in plants to pull carbon from air

Tennessee State will become the first HBCU to add ice hockey

10 Facts About Stress You Should Know
How to pause notifications on Threads
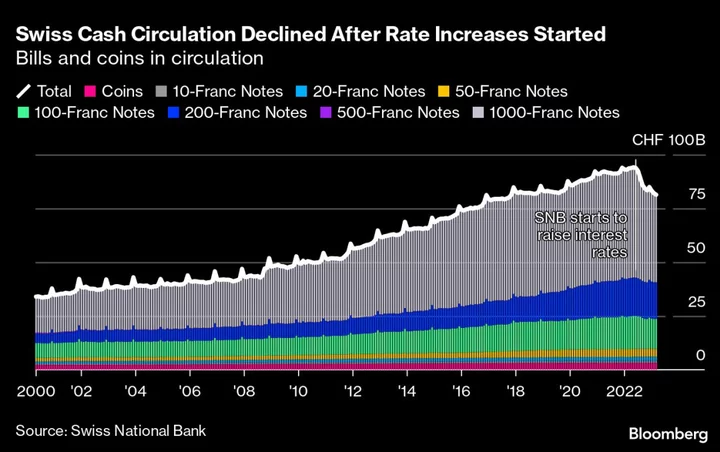
Swiss Fall Out of Love With Cash Amid Soul Searching About Money

Meta Touts Metaverse’s Potential for Job Training and Education

‘Rate limits’ and Twitter chaos: What exactly is Elon Musk doing?